

![월드컵까지 따냈다...스포츠산업 '생태계 파괴자' 된 빈살만[글로벌스트롱맨]](https://image.edaily.co.kr/images/Photo/files/NP/S/2023/11/PS23110500115t.jpg)

![[포토] 폭염 속 휴식취하는 건설 근로자](https://image.edaily.co.kr/images/Photo/files/NP/S/2023/08/PS23080100718t.jpg)

1부① ▶보기 / 1부② ▶보기 / 2부① ▶보기 / 2부② ▶보기[IT벤치마크팀 닥터몰라] 필자가 대학에 들어간 2007년은 컴퓨터의 역사에서는 정말 따분한 해였다. 2005년 봄의 G70 출시를 마지막으로 엔비디아는 만 2년째 아키텍처 업데이트가 없었다. 그러던 2007년 5월, ‘GeForce 8000(G80)’이 출시되었다.
|

2년여 전 출시된 게이밍 콘솔 PS3과 XBOX 360은 바로 다음 세대의 엔비디아 / ATi 양사 GPU에 지대한 영향을 미쳤다. 그것은, 새로운 시각효과 기술이 대두될 때마다 ‘전용 유닛’을 다음 세대 GPU에 탑재하는 것으로 대응하던 흐름을 ‘깡 컴퓨팅 성능’ 하나로 흡수하는 거대한 전환이었다. (이상은 1부 참조)
G80은 역사상 처음으로 ‘역할에 구분을 두지 않은’ 통합 쉐이더 또는 범용 쉐이더 구조를 채택한 칩으로 128개의 통합 쉐이더, 64개의 텍스처 유닛, 24개의 ROP를 탑재했다. 다만 NV30(GeForce FX)와 마찬가지로, 텍스처 어드레스 유닛과 텍스처 필터 유닛의 구성비가 2:1로 비동기되며 유효 텍스처 성능은 종전 32개분 만큼으로 제한되었다.
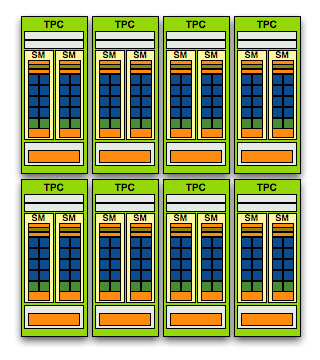
또한 G80은 쉐이더 및 텍스처 유닛 전체에 걸쳐 적용되는 별도의 클럭 도메인을 설정, 칩 내부의 다른 도메인 대비 2~2.5배 이상 고클럭으로 작동하게 함으로써 쉐이더 및 텍스처 성능을 극대화했다. 엔비디아는 이러한 쉐이더 및 텍스처 유닛 집합을 <텍스처 프로세싱 클러스터(TPC)>로 정의하며, 다시 TPC 내부에서 명령어를 발행하는 최소단위를 <스트리밍 멀티프로세서(SM)>로 명명했다. 오늘날까지 이어지는 GPU(-TPC)-SM 구조의 시작이다.
G80은 SM당 8개씩의 쉐이더(앞으로 ALU라는 표기와 혼용할 것이다)를 편성했으며 각각의 SM은 하나의 스케줄러로 명령어를 발행한다. 이러한 SM 두 개와 텍스처 유닛 8개가 TPC를 구성하는데, TPC는 온전한 ‘그래픽 처리’가 일어나는 최소한의 단위이다. G80은 이러한 TPC를 8개 탑재하고 있다.
G80의 ‘틱’에 해당하는 G92는 제조공정 미세화 이외에도 일부 유닛 구성비율이 재조정되었다. 128 ALU를 고수하되, G80의 약점인 텍스처 필터 유닛을 64개로 늘려 비로소 64개분의 텍스처 성능을 발휘할 수 있게 되었고, 반면 비대한 면적을 차지하던 ROP 및 메모리 인터페이스를 2/3로 축소해 16 ROP만을 남긴 것이다. 요약하면 텍스처 성능이 강화되었으나 ROP가 다운그레이드 되어,
|
|
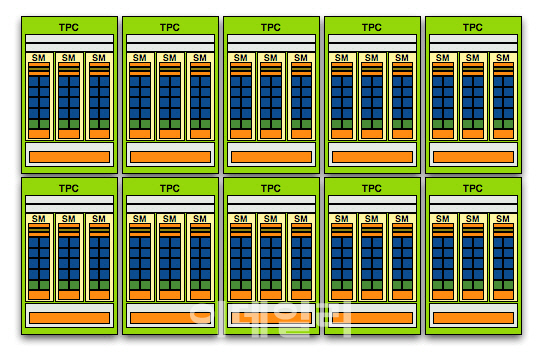
큰 틀에서, GT200과 G80/92의 차이는 GPU(-TPC)-SM으로의 계층 구조를 유지하되 TPC의 구성 방식이 변화한 데 있다. G80/92의 TPC가 2 SM을 탑재한 반면 GT200의 TPC는 3 SM탑재로 바뀌었으며, 이에 따라 ALU와 텍스처 유닛의 비율은 2:1->3:1로 ALU 비중이 높아졌다. Tesla 연산 가속기의 등장이 암시하듯 범용 GPU 컴퓨팅의 저변 확대에 따른 변화로 볼 수 있다. 또한 TPC 자체의 개수가 8->10개로 증가한 점, ROP 개수가 16개에서 32개로 확대된 점 등 변화는 결코 작지 않다.
|

Fermi 아키텍처는 종전의 GPU-TPC-SM으로 이어지는 계층 차상위에 하나의 층위를 신설, TPC 개념을 대체할 <그래픽 프로세싱 클러스터(GPC)>를 도입했다. 뿐만 아니라 종전의 ‘중앙집권형’ 래스터/지오메트리/폴리모프 엔진(이하 래스터 엔진 등으로 통칭)을 GPC마다 하나씩 배치하며 Fermi는 종전의 GPU 개념을 ‘멀티코어화’ 한 것에 가까워졌다. 래스터 엔진은 ROP가 처리할 래스터를 공급하는 역할로, 그 자체는 16 ROP에 대응하며 텍스처 어드레스 유닛-텍스처 필터 유닛 쌍이 1조를 이루듯 공급-처리의 균형이 중요시된다.
또한 SM 레벨에서는 명령어 스케줄러가 1->2개로 증가(
|

종합적으로, GF100/110은 512:64:48의 유닛 구성비율을 갖는 거대 GPU로 GT200과 비교했을 때 ALU 개수가 113% 증가한 반면, ROP는 50% 증가에 그치고 텍스처 유닛은 오히려 20% 감소하는 등 밸런스가 크게 변화한 것이 특징이다. 특히 통상적인 FP32 연산 이외에 FP64 연산에 대응하도록 개편하며 연산 유닛에 투입된 총 트랜지스터 수 증가율은 200%를 뛰어넘는다.
1세대 Fermi의 약점은 여기에 있었다. 연산 성능이 증가한 것에 비해 게이밍 성능 향상폭은 그리 크지 않았고, 그러면서도 발열/소비전력/생산단가가 일제히 상승하는 삼중고가 겹친 것이다. 그러나 엔비디아는 놀랍게도 이들 문제를 같은 세대 내부에서의 아키텍처 혁신으로 해결했다.
|
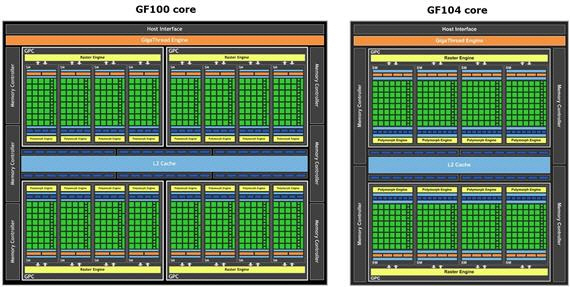
GF104/114의 GPC는 4개의 SM으로 구성(= 48x4 = 192 ALU)되며 GPU 전체는 2개의 GPC로 구성, 전체적으로는 384:64:32의 구성을 취하고 있다. GF100/110와 비교하면 ALU가 25%, ROP가 33% 감소했으나 스케줄러 및 텍스처 유닛의 개수는 같다. 전력 효율은 2배 가까이 향상되어 1세대 Fermi의 오명을 완벽히 씻었다.
이 시기 가시화된 엔비디아의 컴퓨팅/그래픽(게이밍) 아키텍처 분리는 이후 느슨하게 명맥을 이어, 격세대로 컴퓨팅-게이밍용 GPU 아키텍처를 특화시키다가(Kepler-Maxwell) 동일 아키텍처 내에서 최상위 GPU의 종류를 이원화하고(Pascal GP100 / GP102) 마침내 한 세대 내에서 아키텍처 자체를 이원화하는(Volta / Turing) 데까지 이른다.
▶2편에서 계속
필진으로 이대근 씨(KAIST 수리과학 전공)와 이진협 씨(성균관대학교 생명과학 및 컴퓨터공학 전공), 이주형 씨(백투더맥 리뷰 에디터/Shakr 필드 엔지니어) 등이 참여한다.






![[포토]책의날 맞아 시민들에게 책 나눠주는 유인촌 문체부 장관](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042300692t.jpg)
![[포토] 안병우 축산경제 대표, 청정축산 환경대상 시상식](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042300549t.jpg)
![[포토] 하나로마트 창립 29주년 70% 세일](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042300533t.jpg)
![[포토]세계 책의 날 맞아 문체부, 국무회의에서 국무위원들에게 책 선물](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042300428t.jpg)
![[포토]국내최대 오트 함량을 담은 어메이징 오트](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042300304t.jpg)
![[포토]'원내대책회의 참석하는 윤재옥'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042300287t.jpg)
![[포토]안전을 향한 닻을 올리자](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042200782t.jpg)
![[포토]BMW그룹 코리아, 'BMW 그룹 R&D 센터 코리아' 개관](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042200677t.jpg)
![[포토] 중소기업 금융애로 점검 회의](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042200646t.jpg)
![[포토]최은우 '대회 2연패 달성'](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24042100415t.jpg)
